A
Alerts
De mogelijkheid om per email op de hoogte te worden gesteld van nieuw gepubliceerde literatuur in specifieke vakgebieden.
Archivalia
Latijnse term voor archiefstukken.
Artikel
Afzonderlijke bijdrage in een dagblad, tijdschrift of (congres)bundel. In deze cursus wordt met artikel een wetenschappelijk tijdschriftartikel bedoeld.
Attenderingen
De mogelijkheid om per email op de hoogte te worden gesteld van nieuw gepubliceerde literatuur in specifieke vakgebieden.
B
Beroepsgerichte publicaties
Beroepsgerichte of vakpublicaties zijn vooral praktisch van aard en bestemd voor beroepsbeoefenaren in allerlei gebieden.
Bibliografie
Lijst van bibliografische beschrijvingen op een bepaald gebied of van een bepaalde auteur bedoeld om het bestaan en de inhoud van documenten (boeken, tijdschriften of artikelen) te signaleren, onafhankelijk van hun aanwezigheid op een bepaalde plaats. Ook wel literatuurlijst genoemd.
Bibliografisch bestand
Bestand met bibliografische gegevens. Bibliografische bestanden zijn er zowel in papieren als in digitale vorm. De laatste vorm wordt ook vaak database genoemd, al is niet elke database een bibliografie.
Bibliografische gegevens
De titelgegevens om een publicatie te kunnen vinden, ook wel literatuurverwijzing of referentie genoemd. Een lijst van referenties vormt een literatuurlijst of bibliografie.
Bookmark
In Internet Explorer "favorieten" genoemd. Door een bookmark/favoriet te maken kun je een link naar een website of -pagina bewaren zodat je daar later naar terug kunt gaan. In Internet Explorer of Firefox kun je favorieten/bookmarks verzamelen en organiseren.
Booleaans zoeken
Bij ingewikkelde zoekvragen kun je de zoekvraag verfijnen (geavanceerd zoeken) door het combineren van trefwoorden met behulp van Booleaanse operatoren , genoemd naar de Engelse wiskundige George Boole (1816-1854).
Booleaanse operatoren
Booleaanse operatoren zijn logische operatoren. Met behulp van de operatoren
AND,
OR en
NOT kunnen relaties tussen zoektermen worden aangegeven, waardoor er preciezer gezocht kan worden.
- EN (AND): verkleinen van je zoekactie
Zoekactie: computer EN onderwijs.
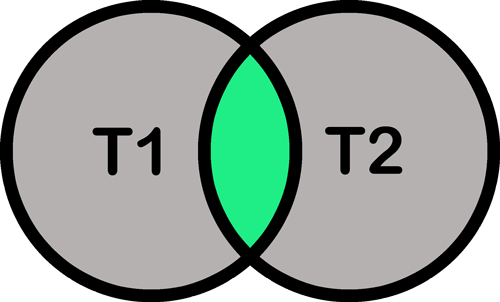
Resultaat: titels waarin beide termen voorkomen.
- OF (OR): vergroten van je zoekactie
Zoekactie: computer OF onderwijs.
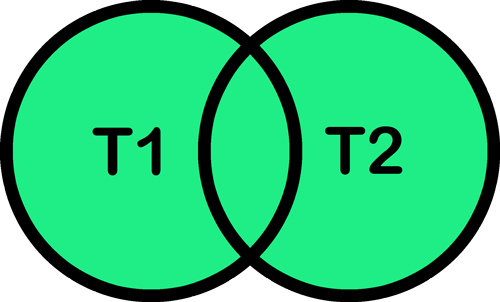
Resultaat: titels waarin tenminste één van beide termen voorkomt.
- NIET (NOT): Verkleinen van je zoekactie (bepaalde term uitsluiten)
Zoekactie: computer NIET onderwijs.
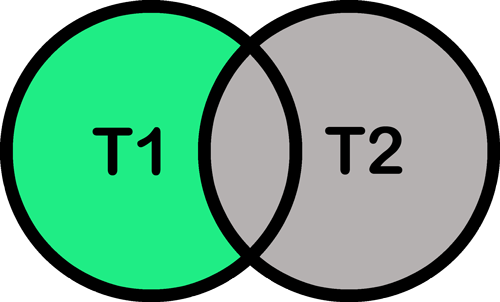
Resultaat: titels waarin de eerste term wel voorkomt, maar de tweede niet.
Pas op met de NIET-operator: je sluit er snel teveel mee uit.
Indien je verschillende operatoren binnen één zoekopdracht gebruikt, weet dan dat
EN/AND en
NIET/NOT beide vóór
OF/OR gaan. In dat geval is het verstandig haakjes te gebruiken. Bijvoorbeeld: (computer of automatisering) en (hoger onderwijs of tertiair onderwijs).
Bouwsteenmethode
Zoekmethode waar je zoveel mogelijk termen met elkaar in één zoekactie combineert.
Bronvermelding
Zie: literatuurverwijzing. Ook wel referentie genoemd.
C
Catalogus
Alfabetisch of systematisch geordende lijst van publicaties (boeken, tijdschriften, DVD's e.d.) die aanwezig zijn of waar toegang toe geboden wordt in een bibliotheek. Iedere publicatie heeft een plaatskenmerk waarmee deze gevonden kan worden op een studiezaal of in een magazijn, of een URL.
Catalogus UB VU
Zie ook: Libsearch. De bibliotheek heeft geen catalogus meer van zichzelf. De collectie van de Bibliotheek van de VU omvat ruim 1.300.000 titels (boeken, tijdschriften, en honderdduizenden tijdschriftenartikelen) van de 15de eeuw tot heden. De collectie is volledig beschreven in de WorldCat catalogus.
Catalogusrecord
Bibliografische beschrijving van een publicatie in de catalogus .
Citatie-index
In een citatie-index vind je van iedere beschrijving van een document de bronnen die de auteur heeft gebruikt (literatuurlijst) en hoe vaak dit document sinds publicatie door anderen wordt vermeld. Dit levert een citatiescore op die gebaseerd is op het aantal referenties .
Citeren
Citeren is het LETTERLIJK OVERNEMEN wat iemand heeft gezegd of geschreven. Je citeert alleen als de letterlijke formulering van de originele bron van belang is voor jouw werkstuk of scriptie.
Als je in EIGEN WOORDEN een zin of alinea weergeeft, wordt dit parafraseren genoemd en bij een langer tekstgedeelte is er sprake van samenvatten
Classificatie
Een systematische of hiërarchische indeling van één of meer wetenschapsgebieden ten behoeve van de onderwerpsontsluiting in bibliotheekcatalogi of informatiebestanden.
Collegiale toetsing
Zie: peer review.
Confirmation bias
Confirmation bias is de neiging die we van nature hebben om onze verwachtingen op een dusdanige manier te toetsen dat ze worden bevestigd.
Congresbundel
Een congresbundel heeft de omvang van een magazine, maar dan in kleiner, handzamer boekformaat. Hierin zijn (samenvattingen van) de bijdragen van alle deelnemers aan een congres opgenomen.
D
Dagblad
Blad dat tenminste zesmaal per week verschijnt.
DARE
DARE staat voor Digital Academic REpositories. VU Dare zal worden uitgefaseerd. In 2017 zijn de functionaliteiten overgebracht naar de research portal
Pure. DAREnet geeft toegang tot full-text publicaties en onderzoeksresultaten van alle Nederlandse universiteiten, KNAW, NWO en een aantal onderzoeksinstellingen. De repository wordt dagelijks aangevuld met publicaties. DAREnet is een deelverzameling van NARCIS. Zie voor meer informatie raadpleeg de website van
Narcis.
Database (of: Databank)
Een database is een verzameling gedigitaliseerde gegevens die zodanig gestructureerd is opgeslagen dat de data eenvouding kunnen worden opgezocht.
Deze gegevens kunnen bestaan uit teksten, bibliografische informatie, statistische gegevens enz., dus zowel
referentiële als feitelijke informatie. Voor bestanden met feitelijke informatie wordt vaak de term databank gebruikt.
In de bibliotheekwereld wordt het begrip database vaak in engere zin gebruikt voor
bibliografische bestanden om deze o.a. te onderscheiden van
catalogi.
In een bibliografische database vind je:
- verwijzingen naar boeken, artikelen, rapporten, congresverslagen, kortom: publicaties
- vaak met samenvattingen
- ongeacht waar ze te vinden zijn (op te zoeken in catalogi)
Directory
Directories zijn door mensen samengestelde en geordende overzichten van webpagina's. Directories bestrijken over het algemeen minder webpagina's dan
zoekmachines, maar ze zijn door de menselijke selectie vaak beter van kwaliteit.
Open Directory is de grootste directory ter wereld en de helaas ter ziele gegane Yahoo! Directory, de meest bekende die bestond sinds 1994.
Startpagina.nl is de bekendste en grootste Nederlandse directory.
Zie ook:
Virtuele bibliotheek.
DNS = Domain Name Service
Systeem dat domeinnamen zoals www.vu.nl vertaalt naar de corresponderende IP-adressen, bestaande uit vier groepen cijfers, zoals 194.113.1.5. De server die deze dienst biedt wordt een DNS-server genoemd.
Document
Informatie die als een eenheid gezien kan worden. Bijv. een boek, hoofdstuk in een boek, tijdschrift of tijdschriftartikel.
Domein (Engels: Domain)
Aanduiding van de herkomst van een webpagina. De top-level domeinnamen zijn geografisch of naar type organisatie ingedeeld: .edu (education), .gov (government), .net (network provider), .com (commercial), .org (non-profit organizations) of afkortingen van landen: .nl (Nederland) en .uk (United Kingdom).
Daarnaast kan er ook een subdomein zijn. Dit is een onderdeel van de 'host' ofwel hoofddomein. Zo is bijv. het adres van de UBVU geen zelfstandig adres, maar maakt onderdeel uit van het adres van de VU: http://www.ubvu.vu.nl/
E
Elektronisch artikel
Tijdschriftartikel in elektronische vorm.
Elektronisch bestand (Engels: e-Resource)
De online bestanden waar de UBVU toegang toe heeft. Elektronische bestanden zijn o.a. catalogi en bibliografieën, maar ook encyclopedieën, woordenboeken, jaarverslagen, kaarten, kranten, e-journals, proefschriften, statistieken en internetbronnen.
Klik
hier voor de elektronische bestanden van de UBVU.
Elektronisch tijdschrift (Engels: e-Journal)
Tijdschrift in elektronische vorm.
E-mail
E-mail was een van de eerste toepassingen van het Internet en is nog steeds een van de meest populaire toepassingen. E-mail is een van de TCP/IP protocollen. Een populair protocol voor het versturen van e-mail is Simple Mail Transfer Protocol (SMTP) en een populair protocol voor ontvangen is POP3.
Embargo
Onder embargo betekent dat een publicatie voor een bepaalde periode nog niet publiekelijk toegankelijk is. Dit kan bijvoorbeeld het geval zijn als de uitgever het niet toestaat, of als er bedrijfsgevoelige informatie in opgenomen is.
Encyclopedie
Beschrijvend, voorlichtend woordenboek (meestal geïllustreerd en alfabetisch).
EndNote
EndNote is een softwarepakket waarmee je een eigen database kunt maken met literatuurververwijzingen. Bovendien kun je de verwijzingen vanuit deze database toevoegen in een MS WORD-document. EndNote is de norm voor referentiesoftware op de VU.
F
FTP = File Transfer Protocol
FTP is het meest gebruikte standaardprotocol waarmee je bestanden (files) en programma's tussen jouw computer en een andere kunt uitwisselen via het Internet.
H
Handboek
Beknopte weergave of samenvatting van een gebied van wetenschap of kunst.
Hodiecentrisme MOETEN WE DIT ERIN HOUDEN?
De tendens om de problemen van hier en nu te beschouwen als eeuwig en algemeen menselijk
HTML
De taal HTML (HyperText Markup Language) is een beschrijvingstaal voor het opmaken van documenten voor het WWW. Het is de standaardtaal voor het web.
HTTP
HTTP (HyperText Transfer Protocol) is de standaardtaal waarmee computers op het Web met elkaar kunnen communiceren. Webadressen beginnen meestal met HTTP://
Humaniora
De Humaniora (ook wel Geesteswetenschappen genoemd) bestaan uit de wetenschapsgebieden Letteren, Theologie en Filosofie.
Letteren kan worden onderscheiden in:
- Algemene Cultuurwetenschappen
- Archeologie
- Germaanse talen
- Romaanse talen
- Geschiedenis
- Griekse en Latijnse Taal en Cultuur
- Kunstgeschiedenis
- Nederlands
- Taalwetenschap
- Literatuurwetenschap
- Talen en culturen van het Oude Nabije Oosten
Hyperlink
Verwijzing in een on line, of digitaal, document naar een ander document of naar een andere plaats in hetzelfde document. Vaak betreft het webpagina's of on line databestanden. Het activeren van de verwijzing - door een muisklik - geeft direct toegang tot het betreffende document.
I
Index
Een index is een (doorzoekbare) lijst van (auteurs)namen, trefwoorden of titels.
In geval van webpagina's kan dit ook een lijst zijn van URL's, afbeeldingen, discussielijsten e.d.
Interbibliothecair Leenverkeer (IBL)
Mensen met een bibliotheek account kunnen boeken lenen of kopieën van artikelen en overig materiaal aanvragen bij andere bibliotheken in Nederland en in het buitenland. Aan IBL zijn kosten verbonden.
Bij de afdeling IBL van de UBVU, Hoofdgebouw, 1
e etage, kun je een IBL-account openen met een deposit. Bij iedere aanvraag worden de kosten van die rekening afgetrokken. Fotokopieën worden rechtstreeks naar je huisadres gezonden, boeken kunnen worden afgehaald bij de bibliotheekbalie op de 1e etage Hoofdgebouw.
Meer informatie vind je op de website van de bibliotheek
> LATEN NAKIJKEN Interbibliothecair lenen
Internet
Internet is een wereldwijd netwerk van netwerken die allemaal het TCP/IPcommunicatie-protocol en een gemeenschappelijke adresruimte gebruiken. Het bestaat uit miljoenen computers over de gehele wereld, waarvan de meeste onderling verbonden zijn door prive-netwerken.
IP-adres
Het netwerkadres van een op internet aangesloten computer. Het IP-adres wordt gebruikt om gegevens via internet van de zender naar de ontvanger te transporteren. Een IP-adres bestaat uit vier getallencombinaties die van elkaar gescheiden zijn door punten, bijvoorbeeld 193.78.11.25.
Elke site heeft bovendien een naam, bijvoorbeeld www.ubvu.vu.nl.
De naam van een site wordt in een bijbehorend IP-adres vertaald door een DNS.
Issue
Zie Tijdschriftnummer.
J
Jaargang
Alle afleveringen, nummers van een tijdschrift, krant of enig ander periodiek werk, die gedurende een (abonnements)jaar uitgegeven worden of zijn.
In het Engels wordt vaak het begrip Volume gebruikt. Volume is echter niet helemaal hetzelfde als jaargang. Een jaargang kan één of meer Volumes bevatten.
L
LCC (Library of Congress Classification)
LCC (Library of Congress Classification) is het classificatiesysteem van de Library of Congress. Deze classificatie is een verfijnd en frequent toegepast classificatiesysteem. Elke vakgebied bestaat uit veel subrubrieken.
LCSH (Library of Congress Subject Heading).
Een LCSH (Library of Congress Subject Heading) is een gestandaardiseerde term uit het onderwerpsregister van de Library of Congress Classification (LCC).
Lenerspas
Studenten VU kunnen, zolang zij aan de VU studeren, lenen met hun collecegekaart. Studenten (en medewerkers) aan een Nederlandse universiteit hebben op vertoon van hun bewijs van inschrijving (geldig dat collegejaar) en geldig legitimatiebewijs recht op een gratis lenerspas, te verkrijgen bij de inschrijfbalie van de UB VU op de 1e etage in het Hoofdgebouw (ruimte 1C-02).
Licentie
Een licentie is een overeenkomst tussen een leverancier van informatie (bv. bestanden) en de UBVU die vastlegt hoe deze informatie wordt aangeboden. Doorgaans betekent dit dat die informatie alleen toegankelijk is via de IP-adressen van de UBVU.
LibSearch
Libsearch is het belangrijkste zoeksysteem van de UB VU.
Hiermee zijn boeken, artikelen, databestanden (link naar databestanden), kaarten, afbeeldingen e.d. te vinden. Hierin bevinden zich niet alleen via de UB uitleenbaar/raadpleegbaar/ on line materiaal, maar er kan ook buiten de collectie worden gezocht in het bezit van, bij OCLC aangesloten, Nederlandse bibliotheken, of internationaal.
LibSearch is een integrale portal die het mogelijk maakt te zoeken in alle (bibliografische) databestanden. In dit zoeksysteem kun je tevens zoeken binnen de eigen (sub)collecties zoals VU Dare, VU Imagebase.
Literatuurlijst
Zie: Bibliografie.
Literatuurverwijzing
Verwijzing naar te raadplegen of geraadpleegde literatuur.
Ook wel referentie genoemd.
Logboek
Boekwerk waarin gebeurtenissen over een onderwerp worden bijgehouden. Onderzoekers houden een logboek (chronologische opsomming) bij die elke stap, elke handeling en elke bron vastlegt.
M
Methodische opbouw
Vaste opbouw voor een artikel of onderzoeksverslag met de volgende onderdelen:
- inleiding met daarin een geformuleerde vraag- of probleemstelling
- methode waarmee men de vraagstelling beantwoordt
- resultaten in de vorm van waarnemingen, metingen, analyseresultaten
- discussie van de resultaten en waarnemingen
- conclusies van het onderzoek
Monografie
Boek over één onderwerp.
Mooc
MOOC staat voor Massive Open Online Courses zijn grootschalige, gratis, open en online cursussen.
N
Nabijheids operator
Zie: proximity operator
NARCIS
NARCIS is dé nationale portal voor wie informatie zoekt over wetenschappers en hun werk. Naast wetenschappers maken ook studenten, journalisten en medewerkers binnen onderwijs, overheid en het bedrijfsleven gebruik van NARCIS.
NARCIS biedt toegang tot wetenschappelijke informatie waaronder (open access) publicaties afkomstig uit de repositories van alle Nederlandse universiteiten, KNAW, NWO en diverse wetenschappelijke instellingen, datasets van een aantal data-archieven, alsmede beschrijvingen van onderzoeksprojecten, onderzoekers en onderzoeksinstituten.
Dit houdt in dat NARCIS (nog) niet gebruikt kan worden als ingang tot complete overzichten van publicaties van onderzoekers. Er zijn echter steeds meer instellingen die al hun wetenschappelijke publicaties via NARCIS toegankelijk maken. Op deze wijze kunnen de publicatielijsten van de wetenschappers zo compleet mogelijk worden gemaakt.
In 2004 is de ontwikkeling van NARCIS gestart als een samenwerkingsproject van KNAW Onderzoek Informatie, NWO, VSNU en METIS in het kader van de dienstenontwikkeling binnen het DARE-programma van SURFfoundation. Dit project heeft de portal NARCIS verwezenlijkt, waarin in januari 2007 de dienst DAREnet is geïncorporeerd. Sinds 2011 is NARCIS een dienst van DANS.
NCC - Nederlandse Centrale Catalogus
De Nederlandse Centrale Catalogus NCC bevat de bibliografische gegevens en de vindplaatsen van circa 14 miljoen boeken en bijna 500.000 tijdschriften in meer dan 400 bibliotheken in Nederland.
O
Onderwerp
Thema dat in een publicatie centraal aan de orde gesteld wordt.
Onzichtbare web (Engels: invisible web)
Het 'onzichtbare' of 'diepe' web betreft informatie die met gewone zoekmachines niet aan de oppervlakte van het web komt. Vaak gaat het om databases, dynamische HTML-pagina's, PDF-,Word- en Flash-bestanden, video's, muziekbestanden en 'real time' informatie. Het 'zichtbare' deel van het Internet bestaat volgens schattingen uit meer dan 14,5 miljard documenten. Het onzichtbare web is zeker 500 maal zo groot. Meer dan de helft van het onzichtbare web is ondergebracht in specifieke databases met elk vaak duizenden pagina's inhoud, die onzichtbaar zijn voor zoekmachines.
ORCiD
ORCiD staat voor Open Researcher en Contributer iD en lijkt een beetje op een creditcardnummer: 0000-0001-6022-2666.
ORCiD is een uniek persoonlijk nummer waarmee onderzoekers hun onderzoeksinformatie gemakkelijk en automatisch kunnen koppelen aan een breed scala aan online databases. Je kunt ORCiD zien als het academische equivalent van je paspoort: het zorgt ervoor dat andere onderzoekssystemen en -diensten weten wie je bent en wat je hebt gedaan. Je zou het ook kunnen zien als een ISBN voor mensen, in plaats van boeken.
Overzichtsartikel (Engels: review)
Geeft een kritische bespreking en vergelijking van eerder gepubliceerde artikelen in een wat breder onderwerpgebied.
P
Parafraseren
Omschrijven in eigen woorden van de inhoud van een (meestal korte) tekstpassage, bijvoorbeeld een zin of een alinea.
Je parafrasering is meestal ongeveer evenveel woorden lang als het origineel, maar past binnen je eigen schrijfstijl.
Peer review (Nederlands: collegiale toetsing)
Toetsing van inhoudelijke kwaliteit door collega-wetenschappers, voorafgaande aan publicatie; vaak georganiseerd door uitgevers van wetenschappelijke tijdschriften.
PiCarta
PiCarta is een verzameling van een aantal bestanden (o.a. een groot aantal Nederlandse bibliotheekcatalogi) waarin tegelijkertijd gezocht kan worden. Picarta is geïntegreerd in de zoekportal LibSearch, maar kan ook apart worden geraadpleegd. De opgenomen bestanden zijn:
- Nederlandse Centrale Catalogus (NCC): bevat de bibliografische gegevens en de vindplaatsen van boeken en tijdschriften in o.a. alle Nederlandse Universiteitsbibliotheken en grote Openbare bibliotheken. De NCC is verbonden met het systeem voor Interbibliothecair Leenverkeer (IBL).
- Online Contents (OLC): bevat de inhoudsopgaven van tijdschriften op alle wetenschapsgebieden (vanaf 1992).
Plaatskenmerk
Unieke code waarmee een boek of tijdschrift in de bibliotheek gevonden kan worden (in de studiezaal of het magazijn). Het plaatskenmerk staat meestal op de rug en aan de binnenzijde van de band, en is meestal een combinatie van cijfers en letters.
Voorbeeld van een UB VU-plaatskenmerk: KR.15048.-
Plagiaat
Het overnemen van stukken, gedachten, redeneringen van anderen en deze laten doorgaan voor eigen werk.
Populair wetenschappelijke publicaties
Populair wetenschappelijke publicaties zijn bedoeld om leken die niet gespecialiseerd zijn op het betreffende vakgebied te informeren over de wetenschap.
Protocol
Het geheel van regels en afspraken (de technische standaard) voor het uitwisselen van gegevens tussen verschillende programma(onderdelen), computers, of netwerken.
Proximity operator (Nederlands: nabijheidsoperator)
De proximity operator of nabijheidsoperator ADJN (adjacent) gebruik je wanneer je zeker weet DAT bepaalde termen in een tekst voorkomen, maar niet precies HOE. De N staat voor het maximaal aantal tussenliggende woorden.
Voorbeeld:
Het effect van ADJ4 het uitgaansleven
- Het effect van het weer op het uitgaansleven
- Het effect van de Euro op het uitgaansleven
Publicatiejaar
Jaar waarin een publicatie is uitgebracht.
Pure
Pure is de research portal van de VU. In dit systeem wordt alle Research output van de VU en VUmc geregistreerd. Zie
research.vu.nl. Pure is de opvolger van
dare en Metis.
Q
Quick and dirty
Wanneer je snel iets te weten wilt komen, of wanneer je informatie zoekt om je te oriënteren op een bepaald onderwerp, kun je gebruikmaken van de zogenaamde quick and dirty methode. Je zoekt in dit geval niet met een uitgebreid zoekplan, maar met behulp van een beperkt aantal zoektermen. Zo kun je zoeken op titel- of trefwoorden of op een combinatie hiervan in een elektronisch bestand of via internet.
R
Redacteur (Engels: Editor)
Persoon die (met anderen) de bijdragen verzamelt voor een tijdschrift, een jaarboek, een reeks enz. of die bijdragen verzamelt en bewerkt voor een verzamelwerk, encyclopedie, woordenboek enz.
Reference Manager
Reference Manager was een softwarepakket waarmee je een eigen database kon maken met literatuurververwijzingen. Het werd met name gebruikt in de Medische- en Bètawetenschappen, Psychologie en Pedagogiek. De uitgever Thomson Reuters is gestaakt met ontwikkeling en ondersteuning van Reference Manager. De Nederlandse universiteiten hebben vervolgens gekozen voor EndNote.
Referentie
De titelgegevens om een publicatie te kunnen vinden, ook wel bibliografische gegevens of literatuurverwijzing genoemd.
Deze bibliografische gegevens omvatten minimaal de auteursnaam en de titel van het document. Gaat het om een publicatie in een groter geheel (bijvoorbeeld een artikel in een tijdschrift of een hoofdstuk in een handboek) dan heb je nog een gegeven nodig, nl. de titel van het document waarin het artikel of hoofdstuk verschenen is.
In een wetenschappelijke publicatie dienen referenties vermeld te worden volgens bepaalde richtlijnen die door de redactie zijn bepaald.
Referentieportal
e-resource die door middel van een zoekinterface toegang biedt tot een verzameling referentiewerken (encyclopedieën en handboeken)
Repositories
Digitale bewaarplaatsen van wetenschappelijke publicaties of onderwijsmiddelen.
Research Portal
De research portal van de VU is een open access portal naar de wetenschappelijke output van de VU.
research.vu.nl. Zie ook
Pure
S
Samenvatting
Een verkorte weergave van een langer tekstgedeelte (bijvoorbeeld een aantal alinea's, bladzijden, een hoofdstuk of een heel boek). Een samenvatting beperkt zich tot de hoofdlijnen en bevat veel minder woorden dan het origineel.
Sleutelbegrippen
Sleutelbegrippen vormen de kernbegrippen in een probleemstelling. Voor een goede probleemstelling is het van belang om per sleutelbegrip synoniemen (ook in een ander taal) en andere gerelateerde termen of trefwoorden te bedenken.
Sneeuwbalmethode
Methode waar je vanuit een bepaald artikel of boek op zoek gaat naar andere literatuur over hetzelfde onderwerp. Dit doe je door na te gaan welke publicaties de auteur van het desbetreffende boek of artikel heeft gebruikt. Maar ook door na te gaan welke andere publicaties verwijzen naar dit boek of artikel. AFBEELDING TOEVOEGEN?
Spider
Spiders (ook wel 'robots' genoemd) speuren het web af naar trefwoorden voor een zoekmachine.
Subject directory
Onderwerpsgidsen, subject directories, subject catalogues, of onderwerpsregisters zijn door mensen ingedeelde overzichten van internetbronnen gesorteerd op onderwerp of categorieën. Zij bevatten slechts een gedeelte van de bronnen van het hele internet. Dit gedeelte is echter wel een kwaliteitsgedeelte van door specialisten uitgezochte sites.
Zie Directory
Subject gateway
Subject gateways zijn overzichten van websites, die door informatiespecialisten zijn samengesteld. Subject gateways bestrijken slechts een klein gedeelte van het totale aanbod op het web! Als gevolg van de zorgvuldige selectie bevatten subject gateways sites van goede kwaliteit. Vaak worden met de links naar deze websites korte beschrijvingen aangeboden. Subject gateways verschillen dus in allerlei opzichten (minder links, annotaties, kwaliteit e.d.) van grote directorieszoals de Yahoo! Directory. De nadruk ligt op wetenschappelijke informatie.
Surfen
Ongericht zoeken op internet. Je springt hierbij van de ene webpagina naar de andere in de hoop daar te vinden wat je zoekt.
Synoniem
Synoniem is een woord dat dezelfde of ongeveer gelijke betekenis heeft als een of meer andere woorden.
T
TCP/IP = Transmission Control Protocol/Internet Protocol
TCP/IP is de verzamelnaam voor alle protocollen waarvan internet gebruik maakt om te communiceren. Er zijn meer dan honderd datacommunicatie-protocollen die alle lid zijn van de TCP/IP familie. Bijvoorbeeld FTP, dat gebruikt wordt voor het transporteren van bestanden. Zo'n protocol bepaalt onder andere hoe de gegevens worden opgesplitst in pakketjes (packets) en dat iedere computer in het netwerk een uniek en eigen IP-adres moet krijgen.
Term
Woord dat in een bepaald vakgebied wordt gebruikt en daar een eigen, scherp omlijnde betekenis heeft.
Thesaurus
Een geordende lijst van termen, met vermelding van hun onderlinge semantische relaties, te gebruiken bij bepaalde (documentaire) werkzaamheden. In gebruik bij sommige bibliografische databases die de UB VU aanbiedt.
Tijdschrift
Publicatie waarvan bij tussenpozen afleveringen verschijnen, bijv. wekelijks, maandelijks of per kwartaal.
Tijdschriftnummer (Engels: Issue)
Aflevering van een tijdschrift.
Trefwoord
Je kunt onderscheid maken tussen vrije trefwoorden en gethesaureerde trefwoorden.
- Vrij trefwoord wil zeggen dat je je zoekvraag vertaald in een of een paar woorden uit de gewone spreektaal.
- Gethesaureerde trefwoorden of gecontroleerde termen zijn woorden of combinatie van woorden waarmee het onderwerp van een publicatie nauwkeurig wordt aangeduid en dat als ingangselement dient in een alfabetische onderwerpscatalogus. In dit geval zijn aan elke titel in de catalogus volgens een thesaurus trefwoorden toegekend die de inhoud van de publicatie zo precies mogelijk omschrijven.
Truncatie
Bij gebruik van truncatie of trunceren met behulp van
wildcards wordt ruimer dan met alleen de ingevulde zoekterm gezocht. Men onderscheidt:
- Rechts trunceren: gezocht wordt naar alle woorden die beginnen met de ingevulde zoekterm (bijvoorbeeld: artikel? vindt zowel artikel als artikelen).
- Links trunceren: gezocht wordt naar alle woorden die eindigen met de ingevulde zoekterm (bijvoorbeeld: ?artikel vindt zowel artikel als tijdschriftartikel).
- Maskeren (middentruncatie): hiermee kan men bij letters binnen een zoekterm aangeven dat op die plek ook andere letters mogen voorkomen (bijvoorbeeld: dire?tie vindt zowel directie als direktie).
Truncatietekens verschillen per zoeksysteem. De meest gebruikte zijn:
*,
? en
$. Kijk in ieder bestand afzonderlijk welke truncatietekens in dat bestand worden gebruikt.
U
URL = Uniform Resource Locator
Een URL is een adres op internet. De URL bestaat uit een aanduiding van een protocol, een domeinnaam en de naam van een pagina of bestand. Een URL is dus een standaard manier om informatiebronnen (www, ftp etc.) binnen internet aan te duiden.
Bijvoorbeeld: http://www.ubvu.vu.nl/index.cfm is een aanduiding voor het http-protocol om in het domein www.ubvu.vu.nl de pagina index.cfm te openen.
V
Verzamelwerk
Een verzamelwerk is een verzameling van essays van verschillende auteurs in één boek samengebracht.
Virtuele bibliotheek (Engels: subject gateway)
Virtuele bibliotheken of subject gateways zijn overzichten van websites, die door informatiespecialisten zijn samengesteld. Subject gateways bestrijken slechts een klein gedeelte van het totale aanbod op het web! Als gevolg van de zorgvuldige selectie bevatten subject gateways sites van goede kwaliteit. Vaak worden met de links naar deze websites korte beschrijvingen aangeboden. Subject gateways verschillen dus in allerlei opzichten (minder links, annotaties, kwaliteit e.d.) van grote directorieszoals de Yahoo! Directory. De nadruk ligt op wetenschappelijke informatie.
VUnetID
Met een VUnetID en wachtwoord kan iedere VU-student en -medewerker van buiten de VU-campus de e-resources en e-journals die de bibiliotheek aanbiedt via het internet benaderen.
Meer over toegang buiten de campus lees je op de website van de universiteitsbibliotheek:
www.ub.vu.nl/nl/faciliteiten/toegang-buiten-de-campus.
W
Web of Science
Bibliografisch bestand dat vrijwel alle wetenschapsgebieden omvat.
LIBGUIDE VERWIJZING OK? Web of Science is opgebouwd uit diverse databases waaronder:
- Science Citation Index Expanded
- Social Sciences Citation Index
- Arts & Humanities Citation Index
Webpagina
Document op een webserver. De informatie in het document kan onder meer bestaan uit tekst, geluid of beeld en hyperlinks naar andere webpagina's.
Webserver
Een met internet verbonden computer waarop documenten worden gepubliceerd.
Website
Het geheel aan informatie dat een persoon of een organisatie op een bepaalde plaats (aangeduid met URL) binnen het Web zet.
Wetenschappelijk woordenboek
In een wetenschappelijk woordenboek worden begrippen van één of alle vakgebieden beschreven. De begrippen zijn gebaseerd op wetenschappelijke artikelen en (hand)boeken.
Wetenschappelijke encyclopedie
In een wetenschappelijke encyclopedie worden (korte) beschrijvingen van begrippen en (al dan niet uigebreide) wetenschappelijke artikelen over afzonderlijke onderwerpen of complete vakgebieden gepubliceerd volgens de stand van kennis op dat moment. Ze zijn gebaseerd op wetenschappelijke artikelen en boeken.
Wetenschappelijke publicaties
Wetenschappelijke publicaties worden geschreven door wetenschappers voor wetenschappers. Het doel van deze publicaties is om resultaten van onderzoek aan elkaar te presenteren, over de betekenis daarvan te discussiëren en hypothesen en theorieën op te stellen.
Wildcard
Een teken - kan zijn een * of ? of $ - dat aangeeft dat op de aangegeven plaats in het woord één of meer willekeurig andere teken mag staan. Dit is handig als een woord op meerdere manieren gespeld kan worden. Zie ook Truncatie.
Verschillende systemen gebruiken verschillende symbolen als wildcards. Kijk in de helpfunctie van het systeem.
Voorbeeld: Met de zoekvraag produ*t krijg je resultaten waarin zowel de woorden product als produkt voorkomen.
WorldCat
Met WorldCat krijgt u toegang tot de collecties en diensten van meer dan 10.000 bibliotheken over de hele wereld
World Wide Web
Wereldwijde verzameling van sites gebaseerd op het HyperText Transfer Protocol (HTTP). Multimedia en hypertext zijn de belangrijkste kenmerken van het world wide web.
Z
Zoekmachine (Engels: search engine)
Programma om informatie op internet te zoeken op trefwoord of op een combinatie van trefwoorden. De zoekmachine onderhoudt een database (index) van trefwoorden en vindplaatsen met behulp van een spider. Bij de grootste zoekmachine Google bevat de database meer dan 8 miljard pagina's en Yahoo! 3 à 4 miljard. Met een zoekmachine zoek je in deze database en NIET op het web zelf!.
Gebruik een zoekmachine wanneer je snel iets over een specifiek of specialistisch onderwerp of een bepaald document wilt zoeken, of wanneer je zoveel mogelijk informatie over een bepaald onderwerp wilt vergaren. Zoek je gegevens over een breder onderwerp, dan is een onderwerpsgids een beter startpunt.
Zoekoperator
Hulpmiddel bij het verfijnen van zoekacties. Bijv. Booleaanse operator, truncatie en zoekstring.
Zoeksleutel
Een zoeksleutel is een manier om publicaties te vinden.
De meeste zoeksleutels zoeken naar universele kenmerken van een publicatie. Bijv. auteur, titel, woord uit de titel, ISBN, ISSN. In welk bestand je ook zoekt, deze kenmerken zijn altijd hetzelfde.
Enkele zoeksleutels, zoals trefwoord of onderwerp, zoeken naar kenmerken die variabel zijn. In het ene bestand wordt bijv. als trefwoord 'tweede wereldoorlog' gehanteerd; in het andere 'second world war' of 'World war II'.
Zoekstring (Engels: phrase searching)
Een zoekstring bestaat uit meerdere woorden binnen aanhalingstekens, bijv. “quantum theory”.
 When searching for research data, you will often find that the data you need is spread over different databases. Let's say you are interested in the relationship between natural disasters and economic growth, as in the article by Skidmore and Toya (2002). Data on long-run economic growth is available from the . The International Disaster Database has data on natural disasters. However, if you want to quantify the relationship between disasters and growth, you will probably need to have information from both sources combined in a single dataset. In this section, we will give some guidelines to achieve that goal.
When searching for research data, you will often find that the data you need is spread over different databases. Let's say you are interested in the relationship between natural disasters and economic growth, as in the article by Skidmore and Toya (2002). Data on long-run economic growth is available from the . The International Disaster Database has data on natural disasters. However, if you want to quantify the relationship between disasters and growth, you will probably need to have information from both sources combined in a single dataset. In this section, we will give some guidelines to achieve that goal.